Results Dashboard
Static viewer for fixed-seed comparisons, PPO metrics, BC validation curves, and local CSV uploads.
Open dashboardAscensionAI is a from-scratch RL system for Ironclad that went from a live-game PPO plateau to the project's first winning agents on a headless C++ simulator — 1-ply replay-search combat plus a diagnose-first macro stack, every change A/B-tested at 150 fixed seeds.
June 17, 2026: the deployed agent is mainline_v3 on the headless sts_lightspeed simulator — 1-ply replay-search combat plus a diagnose-first macro stack — averaging floor 26.1 with 9 wins / 150 fixed seeds (6.0%), the project's first winning agents. This followed a June 10 pivot off the throughput-starved live game, which had plateaued at ~14.7 floor and 0 wins across ~21,700 games. A controlled variant series then showed combat execution — not reward, capacity, or deck-building — was the universal wall: holding everything else fixed and playing combat with search alone drove average floor 14.7→26.4. Wins followed from a stacked, individually A/B-tested set of non-combat levers.
Static viewer for fixed-seed comparisons, PPO metrics, BC validation curves, and local CSV uploads.
Open dashboardTrainer/worker topology, checkpoint sync, stale rollout rejection, crash handling, and scaling points.
Open docsA 1-ply replay search plays combat far better than any learned feed-forward policy could (boss 75–88% vs 44%). Holding drafting/pathing fixed and replacing only combat decisions nearly doubled run depth — combat was the universal wall.
Read the variant seriesTraining moved off the ~90-games/hour live game onto the sts_lightspeed C++ sim (~17k games/hr) via a process-separated worker/trainer stack, demoting the live game to a transfer-eval oracle.
Reproducible summaries for BC baseline, parallel PPO, and fixed-seed evaluation.
Open reportsPlain-English reference for the training, evaluation, environment, plotting, and logging scripts.
Read script guideFull architecture of the live-game RL system: BC warm-start, PPO fine-tuning, action masking, parallel rollouts, and headless cloud deployment. The later headless-simulator era (search-combat → mainline_v3) is documented in the Experiments reports 009–011.
Read writeup · PDFMore projects, background, and contact information.
Visit justinchan.dev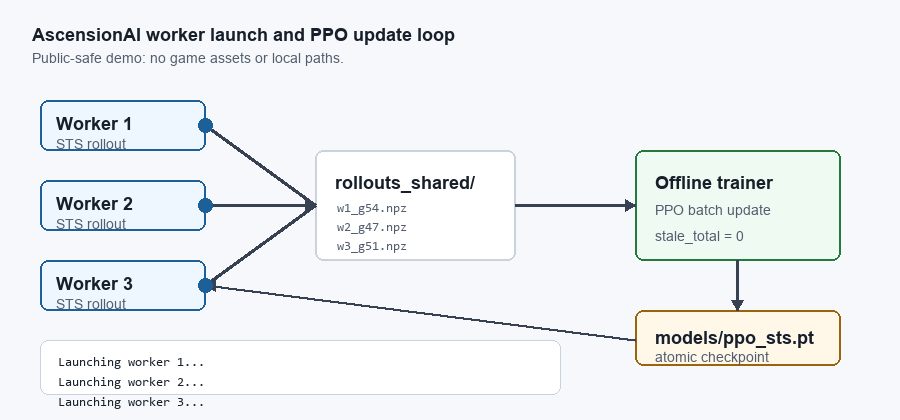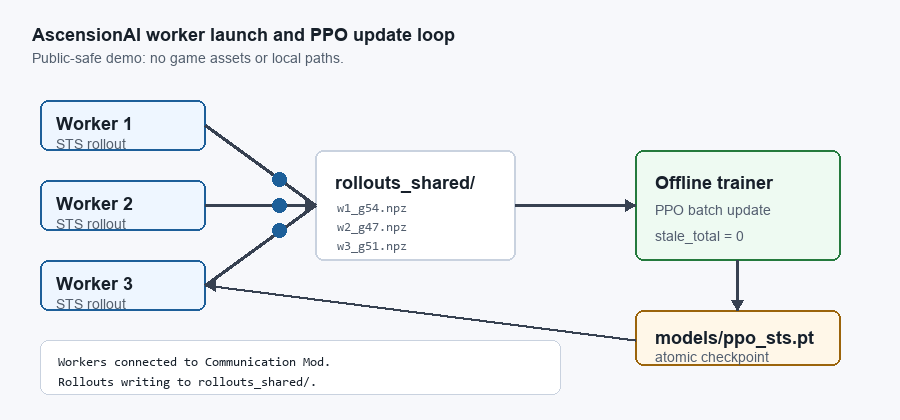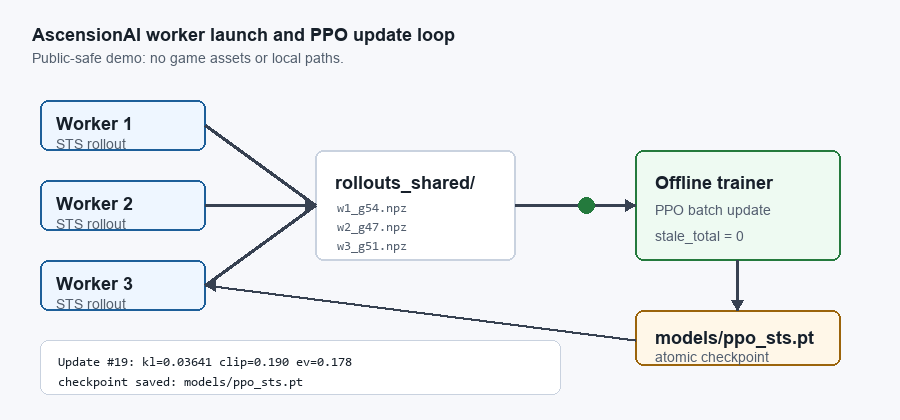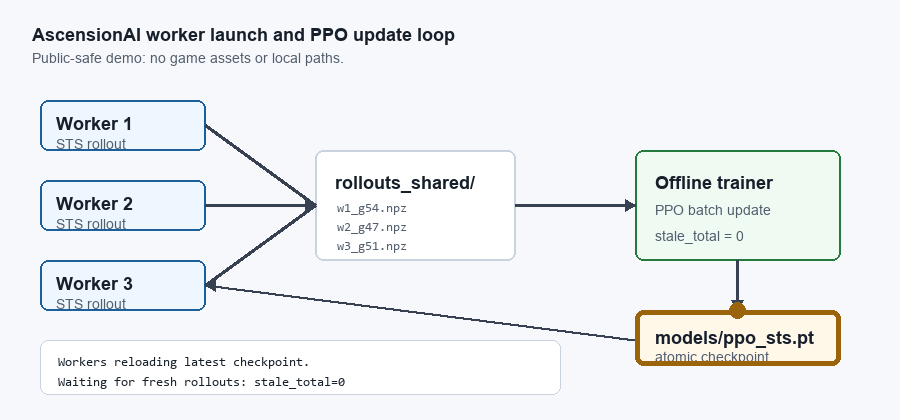
AscensionAI trains as a distributed worker/trainer loop: rollout workers write checkpoint-tagged data, an offline trainer consumes fresh batches, saves an updated checkpoint, and workers reload the policy for the next cycle. The animation shows the live-game version; the headless simulator uses the same process-separated pattern at ~190× the throughput.
Across 150 fixed seeds, the deployed mainline_v3 averages floor 26.1 with 9 wins (6.0%) — the project's first agents to complete runs, after 0 wins across ~21,700 live games and the entire simulator variant series. Each win came from a diagnosed, individually A/B-tested lever stacked on search-combat. The live-game PPO peak below is kept as the historical baseline the pivot left behind.
150 fixed seeds: 26.1 avg floor, 9 wins (6.0%). Tempo-targeted smithing — upgrade the highest-impact card, not a Strike — for the biggest single-lever floor gain, at no HP cost.
View report150 fixed seeds: 24.9 avg floor, 7 wins (4.7%). Search-combat + deck hygiene + AoE/draw role scorer + conservative smith — the project's first wins.
View report200 eval games: 14.66 avg floor, 38.1% boss WR, 0 wins. The throughput-starved live-game plateau that motivated the headless-simulator pivot.
View report